中级计量经济学
(硕士研究生2019年秋)
课程复习提要
教材和题型
1. 参考教材和教学资源
Gujarati, D. and D. Porter. Basic Econometrics 5ed [M], McGraw-Hill Education,2008. 古扎拉蒂的《计量经济学基础》(上下册)。
课程网站:https://home.huhuaping.com/
- 课件材料
- 参考资料
- 复习提要
- 往年真题
2. 考试题型
论述题:主要考察对相关理论的理解和系统认识,需要轻度的符号表达。答对要点即可得分。
分析题:主要考察对相关知识点的实证分析应用,需要会看懂主要的软件报告(Eviews、R、等等),结合数据报告作答。
何种软件出分析报告,并不是关键。因为各种软件结果大抵类似。
分析题一般会围绕2-3个案例数据展开,分大题分小题,一直提问下去……!
3. 其他事项
不要紧张,没有想象的那么难!
下面,就好好看复习要点吧!————》》》》》
第一部分:多元回归分析(回顾本科阶段计量知识)
(一)约定的记号和写法
课程要求:熟练、准确地书写基本的模型和函数形式;
- 总体回归模型(PRM):
理论表达式:形如\(Y_i= \beta_1 + \beta_2X_{2i}+ \beta_3X_{3i}+u_i\)
- 总体回归函数(PRF):
理论表达式:形如\(E(Y_i|X_i)= \beta_1 + \beta_2X_{2i}+ \beta_3X_{3i}\)
- 样本回归模型(SRM):
理论表达式:形如\(Y_i= \hat{\beta}_1 + \hat{\beta}_2X_{2i}+ \hat{\beta}_3X_{3i}+e_i\)
数值表达式:形如\(Y_i= 20.5 + 0.6X_{2i}+ 1.4X_{3i}+e_i\)
- 样本回归函数(SRF):
理论表达式:形如\(\hat{Y}_i= \hat{\beta}_1 + \hat{\beta}_2X_{2i}+ \hat{\beta}_3X_{3i}\)
数值表达式为:形如\(\hat{Y}_i= 20.5 + 0.6X_{2i}+ 1.4X_{3i}\)
(二)阅读统计软件给出的分析报告
课程要求:会熟练、正确阅读统计软件给出的各类分析报告,理解其中的关键信息和内涵。这些分析报告包括:传统的多元回归分析报告;时间序列分析报告;联立方程分析报告;logistics回归分析报告;以及各种计量检验的辅助分析报告(如异方差white检验报告)等。
根据统计软件的不同(stata;Eview;R ……),各种分析报告呈现形式略有差异,但基本要素和信息都大抵一致。
起码要了解下面一些报告形式:
- 整理好的精炼报告(形式1:多行方程表达法)。
根据统计软件的原始报告,往往是选取最关键的信息,经过整理并以多行方程的形式呈现,精炼报告的形式一般为:
\[\begin{equation} \begin{alignedat}{999} &\widehat{lprice}=&&+0.65&&-0.10lquan&&-0.08mon\\ &\text{(t)}&&(1.4753)&&(-1.9541)&&(-0.7961)\\ &\text{(se)}&&(0.4408)&&(0.0501)&&(0.1042)\\ &\text{(cont.)}&&-0.08tue&&-0.07wed&&+0.05thu\\ &\text{(t)}&&(-0.7979)&&(-0.6801)&&(0.5341)\\ &\text{(se)}&&(0.1048)&&(0.1077)&&(0.1008)\\ &\text{(cont.)}&&+0.29stormy&&+0.09cold&&-0.15change\\ &\text{(t)}&&(3.6030)&&(1.2080)&&(-2.0013)\\ &\text{(se)}&&(0.0815)&&(0.0713)&&(0.0738)\\ &\text{(fitness)}&& n=111;&& R^2=0.2610;&& \bar{R^2}=0.2030\\ & && F^{\ast}=4.50;&& p=0.0001\\ \end{alignedat} \tag{1} \end{equation}\]
- 整理好的精炼报告(形式2:表格列示法)。
根据统计软件的原始报告,往往是选取最关键的信息,经过整理以表格形式呈现,表格列示法的形式一般为:
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 0.65 | 0.44 | 1.48 | 0.14 |
| lquan | -0.10 | 0.05 | -1.95 | 0.05 |
| mon | -0.08 | 0.10 | -0.80 | 0.43 |
| tue | -0.08 | 0.10 | -0.80 | 0.43 |
| wed | -0.07 | 0.11 | -0.68 | 0.50 |
| thu | 0.05 | 0.10 | 0.53 | 0.59 |
| stormy | 0.29 | 0.08 | 3.60 | 0.00 |
| cold | 0.09 | 0.07 | 1.21 | 0.23 |
| change | -0.15 | 0.07 | -2.00 | 0.05 |
- 原始报告——传统多元回归分析的
R软件分析报告
一般呈现为:
Call:
lm(formula = mod_mult, data = fultonfish)
Residuals:
Min 1Q Median 3Q Max
-0.835 -0.240 0.027 0.252 0.726
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.6504 0.4408 1.48 0.14321
lquan -0.0978 0.0501 -1.95 0.05343 .
mon -0.0830 0.1042 -0.80 0.42780
tue -0.0836 0.1048 -0.80 0.42677
wed -0.0732 0.1077 -0.68 0.49801
thu 0.0538 0.1008 0.53 0.59441
stormy 0.2937 0.0815 3.60 0.00049 ***
cold 0.0861 0.0713 1.21 0.22986
change -0.1478 0.0738 -2.00 0.04801 *
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.34 on 102 degrees of freedom
Multiple R-squared: 0.261, Adjusted R-squared: 0.203
F-statistic: 4.5 on 8 and 102 DF, p-value: 0.000104- 原始报告——时间序列回归分析的
R软件分析报告
形式一般为(以\(ARMA(2,0)\)模型为例):
Series: fultonfish$lprice
ARIMA(2,0,0) with non-zero mean
Coefficients:
ar1 ar2 mean
0.908 -0.198 -0.186
s.e. 0.095 0.095 0.079
sigma^2 estimated as 0.0625: log likelihood=-2.5
AIC=13 AICc=13 BIC=24
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.0023 0.25 0.2 Inf Inf 0.96 -0.0028- 原始报告——联立方程回归分析的
R软件报告
形式一般为(以两个方程的联立方程组回归分析为例。大家重点关注回归部分,诊断部分不需要关注!):
原始分析报告:
systemfit results
method: 2SLS
N DF SSR detRCov OLS-R2 McElroy-R2
system 222 213 110 0.107 0.094 -0.598
N DF SSR MSE RMSE R2 Adj R2
eq1 111 105 52.1 0.496 0.704 0.139 0.098
eq2 111 108 57.5 0.533 0.730 0.049 0.032
The covariance matrix of the residuals
eq1 eq2
eq1 0.496 0.396
eq2 0.396 0.533
The correlations of the residuals
eq1 eq2
eq1 1.000 0.771
eq2 0.771 1.000
2SLS estimates for 'eq1' (equation 1)
Model Formula: lquan ~ lprice + mon + tue + wed + thu
<environment: 0x000000001487ce48>
Instruments: ~mon + tue + wed + thu + stormy
<environment: 0x000000001487ce48>
Estimate Std. Error t value
(Intercept) 8.5059 0.1662 51.19
lprice -1.1194 0.4286 -2.61
mon -0.0254 0.2148 -0.12
tue -0.5308 0.2080 -2.55
wed -0.5664 0.2128 -2.66
thu 0.1093 0.2088 0.52
Pr(>|t|)
(Intercept) <0.0000000000000002 ***
lprice 0.010 *
mon 0.906
tue 0.012 *
wed 0.009 **
thu 0.602
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.704 on 105 degrees of freedom
Number of observations: 111 Degrees of Freedom: 105
SSR: 52.09 MSE: 0.496 Root MSE: 0.704
Multiple R-Squared: 0.139 Adjusted R-Squared: 0.098
2SLS estimates for 'eq2' (equation 2)
Model Formula: lquan ~ lprice + stormy
<environment: 0x000000001487ce48>
Instruments: ~mon + tue + wed + thu + stormy
<environment: 0x000000001487ce48>
Estimate Std. Error t value
(Intercept) 8.62835 0.38897 22.18
lprice 0.00106 1.30955 0.00
stormy -0.36325 0.46491 -0.78
Pr(>|t|)
(Intercept) <0.0000000000000002 ***
lprice 1.00
stormy 0.44
---
Signif. codes:
0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.73 on 108 degrees of freedom
Number of observations: 111 Degrees of Freedom: 108
SSR: 57.522 MSE: 0.533 Root MSE: 0.73
Multiple R-Squared: 0.049 Adjusted R-Squared: 0.032 整理后的分析报告
| eq | vars | Estimate | Std. Error | t value | Pr(>|t|) |
|---|---|---|---|---|---|
| eq1 | (Intercept) | 8.5059 | 0.17 | 51.1890 | 0.000 |
| eq1 | lprice | -1.1194 | 0.43 | -2.6115 | 0.010 |
| eq1 | mon | -0.0254 | 0.21 | -0.1183 | 0.906 |
| eq1 | tue | -0.5308 | 0.21 | -2.5518 | 0.012 |
| eq1 | wed | -0.5664 | 0.21 | -2.6620 | 0.009 |
| eq1 | thu | 0.1093 | 0.21 | 0.5233 | 0.602 |
| eq2 | (Intercept) | 8.6284 | 0.39 | 22.1826 | 0.000 |
| eq2 | lprice | 0.0011 | 1.31 | 0.0008 | 0.999 |
| eq2 | stormy | -0.3632 | 0.46 | -0.7813 | 0.436 |
(三)理解多元回归系数的含义、计算拟合值或预测值、拟合优度
课程要求:会正确理解回归系数的经济学含义;给定已知条件下,会利用回归方程结果,计算出Y的拟合值或预测值;掌握拟合优度的具体指标。
- 系数的含义:
双对数模型\(ln(Y_i)= \hat{\beta}_1+ \hat{\beta}_2ln(X_i)+ e_i\)中,\(\hat{\beta_1}\)表示Y对X的弹性。
- 计算\(Y_i\)的拟合值或预测值:
模型\(ln(Y_i)=20+ 0.6X_i+ e_i\),在给定\(X_i=10\)时,\(Y_i\)的拟合值\(\hat{Y}_i=e^{(20+0.6 \ast 10)}=\) 195729609428.84
- 拟合优度的主要指标:
在OLS估计法下的多元回归,其拟合优度指标有可决系数\(R^2\)或调整可决系数\(\bar{R}^2\)。
(注意,在Logistics回归里,采用的是ML估计法,其拟合优度测度另有相应指标!)
(四)主要的统计学检验和计量经济学检验
课程要求:熟练掌握假设检验的基本原理和过程;根据不同检验目的和手段,会进行基本的检验和判断。
- 假设检验的基本过程
step1: 提出原假设\(H_0\)和备择假设\(H_1\)
step2: 构造合适的样本统计量(一般是\(Z^{\ast}\)统计量、\(t^{\ast}\)统计量、\(F^{\ast}\)统计量、\(\chi^{2\ast}\)统计量等)
step3: 给定显著性水平(如\(\alpha=0.05\))和自由度(\(f\))下查出理论分布值,如\(Z_{0.975}(f_z);t_{0.975}(f_t);F_{0.95}(f_1, f_2);\chi^2_{0.95}(f_{\chi})\)等。(注意:对称性分布如Z分布和t分布,采用双尾查表,得到右侧正值;非对称的F分布和\(\chi^2\)分布),采用单尾查表。其次,不同情况下,自由度f的取自要视情况而定,需要牢记自由度f!)
step4: 比较样本统计量与理论分布值的大小关系,得出检验结论。如果样本统计量大于理论分布值,则表明在\(1-\alpha=95\%\)置信度下是显著的,应显著的拒绝原假设\(H_0\);如果样本统计量小于理论分布值,则表明在\(1-\alpha=95\%\)置信度下是不显著的,也即不能显著的拒绝原假设\(H_0\),所以暂时接受原假设\(H_0\)。
注意1:原假设和备择假设,在不同检验目的下会不相同。怎么才能更好地记忆呢?一条基本的法则就是:原假设\(H_0\)则一般是希望被拒绝的,从而希望得到备择假设\(H_1\)。——也就是说,原假设\(H_0\)永远只是“稻草人”,我们希望它被打到,真正的醉翁之意实际上是备择假设\(H_1\)!
注意2:除了使用step4的办法,我们还可以直接看样本统计量对应的p值,也可以判断是显著还是不显著!
- 重要的几类检验:
t检验:主要是回归系数显著性检验……
F检验:广泛用于模型整体显著性检验、约束条件模型检验等……
\(\chi^2\)检验:用于异方差怀特检验、logit回归的模型整体显著性检验(对数似然LR检验)……
(五)虚拟变量回归
课程要求:掌握定性变量如何用一组虚拟变量来表达;有截距模型和无截距模型的差异;给定初始条件,计算Y的拟合值或预测值。
- 给定条件下Y期望值的表达和计算:
给定{lquan=2.3, mon=1, tue=0, wed=0, thu=0,stormy=1, cold=1, change=0 }下,\(E(lprice|...)\)可以表达和计算为:
\[\begin{align} \begin{split}E(lprice&|lquan=2.3;mon=1.0;tue=0.0;wed=0.0;thu=0.0;\\ &stormy=1.0; cold=1.0;change=0.0)\\=&+\beta_{1}+\beta_{2}(2.3)+\beta_{3}(1)+\beta_{4}(0)+\beta_{5}(0)\\&+\beta_{6}(0)+\beta_{7}(1)+\beta_{8}(1)+\beta_{9}(0)\\=&+\beta_{1}+2.3\beta_{2}+\beta_{3}\\&+\beta_{7}+\beta_{8}\\\end{split}\end{align}\]
(六)违背经典假设:多重共线性问题
内容要点:
- 什么是多重共线性问题?
- 多重共线性问题有什么后果?
- 如何诊断多重共线性?
- 如何矫正多重共线性问题?
课程要求:掌握多重共线性问题的主要诊断方法,尤其是方差膨胀因子(VIF)。主要的修正方法有哪些?
(七)违背经典假设:异方差问题
内容要点:
- 什么是异方差问题?
- 异方差问题有什么后果?
- 如何诊断异方差问题?
- 如何矫正异方差问题?
课程要求:掌握异方差问题的主要诊断方法,尤其是观测残差图初步识别法和怀特异方差检验(White test)法。主要的修正方法有哪些?——加权最小二乘法(WLS)
怀特异方差检验(White test)法:
需要注意怀特辅助诊断方程的设置特点!
怀特检验将会采用\(\chi^2\)统计量进行假设检验!
熟记原假设和备择假设!
(八)违背经典假设:自相关问题
内容要点:
- 什么是自相关问题?
- 自相关问题有什么后果?
- 如何诊断自相关问题?
- 如何矫正自相关问题?
课程要求:掌握自相关问题的主要诊断方法,尤其是观测残差图初步识别法、德宾-沃森差检验(Durbin-Wasen)法、LM检验法。主要的修正方法有哪些?——广义差分方程法(GDE)
第二部分:受限因变量模型
课程要求:理解受限因变量回归模型的构建原理;掌握probit模型和logit模型的异同;重点要会解读logit回归模型的分析报告,尤其是回归系数的含义。
(一)二分类受限因变量模型
重要的知识点包括:
- 识记logit累积概率函数和probit累积概率函数:
能写出二者的函数表达式;能识别probit累积概率密度曲线和logit累积概率密度曲线(见书本第15章,pg:571)。
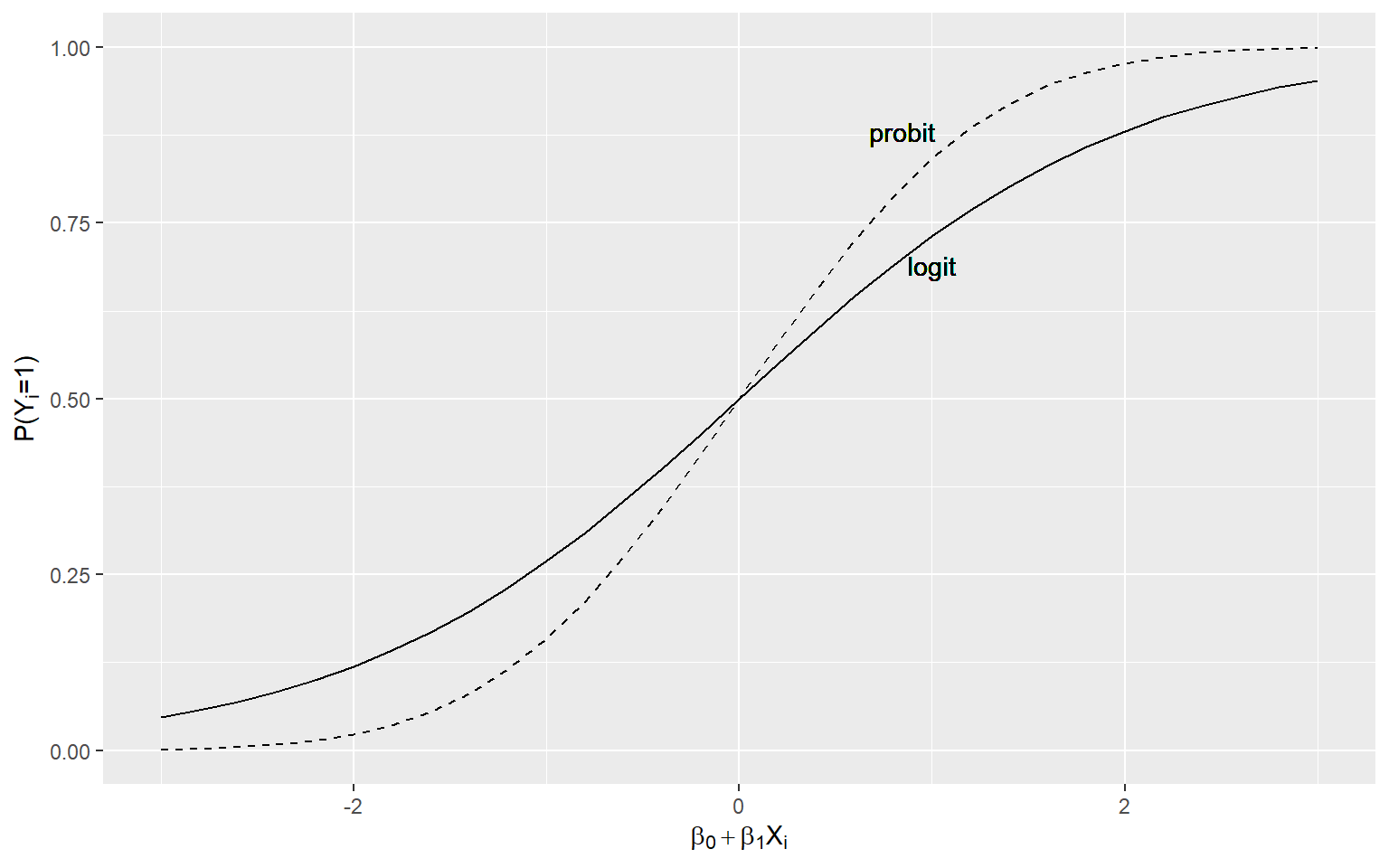
图1: probit模型和logit模型下的累积概率曲线
请指出图1中,probit累积概率曲线和logit累积概率密度曲线分别是哪一条?并请写出其累积概率函数表达式。
- 理解logit模型及表达:
令\(Z_i=\beta_0+\beta_1X_i\)
\[L_i=ln(\frac{P_i}{1-P_i})=Z_i=\beta_0+\beta_1X_i\]
- 掌握logit模型的拟合优度指标(见书本第15章,pg:562)
计数\(R^2=\frac{Y_i的正确预测数}{Y_i的总观测数n}\)(重点掌握)。
麦克法登\(R^2\)(Mcfadden \(R^2\))。
- logit回归方程的解读,尤其是回归系数的含义(见书本第15章,pg:562-563)
主要有三个层面的解读和计算:
简单系数解读(没多大意义)。大概过程是:(假定\(X_2\)也是二分类变量,且X_2前的回归系数\(\hat{\beta}_2=0.6\)),若\(X_2\)由0变为1的话,则(保持其他因素不变下)Logit估计值\(L_i\)将变为0.6……
机会比率解读(有那么点实际意义)。大概过程是:(假定Y为二分类变量,\(X_2\)也是二分类变量,且X_2前的回归系数\(\hat{\beta}_2=0.6\)),若\(X_2\)由0变为1的话,则(保持其他因素不变下)\(Y=1\) 与 \(Y=0\)的机会比率为1.82……
给定条件下Y=1的实际发生概率。计算稍微复杂,请自行训练和脑部吧!
(二)多分类受限因变量模型
多项Logit /Probit回归模型
有序Logit / Probit回归
第三部分:时间序列分析
课程要求:
1. 时间序列的平稳性检验——定量方法
(见书本第21章,pg:764)
对于时间序列变量,首先应该检验它是否平稳。
我们需要重点关注采用增广迪基-富勒检验法(Augmented Dickey-Fuller Test,ADF)检验时间序列变量是否平稳。
要注意增广迪基-富勒检验法(Augmented Dickey-Fuller Test)的基本检验原理
要会看增广迪基-富勒检验法(Augmented Dickey-Fuller Test)的检验分析报告,并正确得出平稳性检验的结论。
很遗憾,书中只给了一个不太实用的分析报告——估计你们也还是看不懂。
下面给出R软件的增广迪基-富勒检验法(Augmented Dickey-Fuller Test)检验报告,你们自己要学会看懂!!(这个检验法经常要用到,所以还是咬咬牙搞定它吧!!)
Augmented Dickey-Fuller Test
data: fultonfish$lprice
Dickey-Fuller = -5, Lag order = 4, p-value =
0.01
alternative hypothesis: stationary2. 时间序列的波动模式——初步的图形方法
如果时间序列变量是平稳的,那么我们就可以很快对其进行平稳性序列建模并预测啦!
但是……,平稳性序列建模有很多种形式啊——AR(p)模型,或者MA(q)模型,或者ARMA(p,q)模型,或者ARIMA(p,d,q)模型……。你选哪一种呢?(抓狂)。
还好,我们先给一个简单一点的图形判断规则吧:
直接看该时序变量的自相关图(PAC)和偏自相关图(PAC)吧。什么图形会匹配什么样的模型,也是有一个经验法则的(好好参看书本第22章,pg:790页吧!!!!)。

至于自相关图(PAC)和偏自相关图(PAC),大概长成这个样子喽:
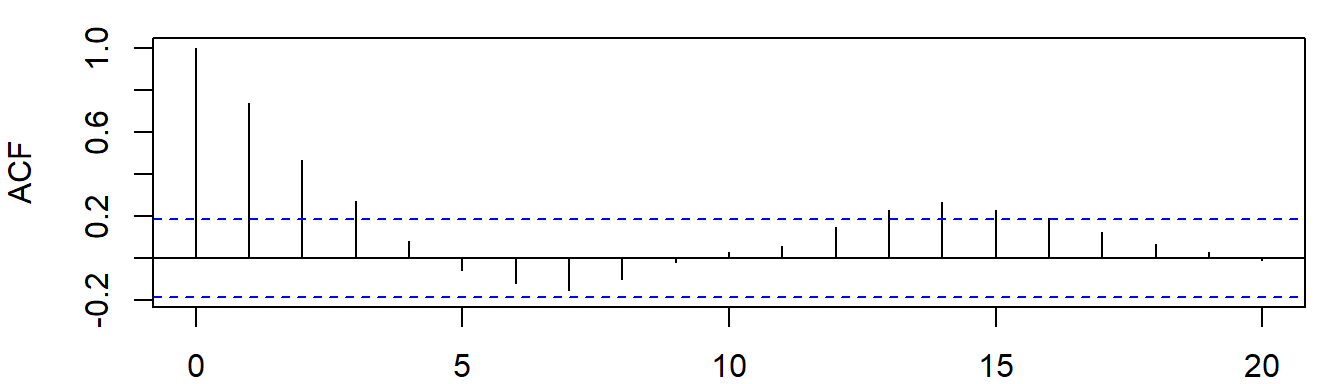
图2: 对数化价格变量lprice的自相关图
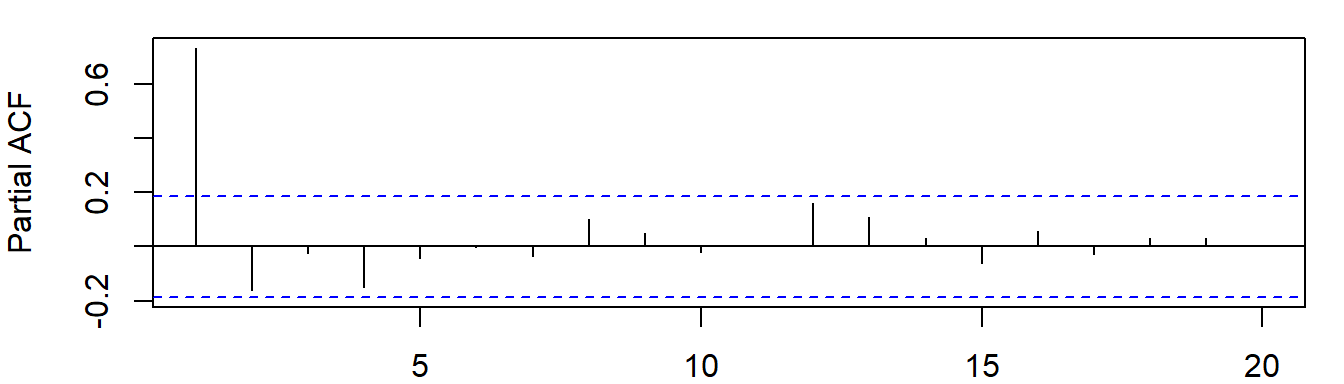
图3: 对数化价格变量lprice的偏自相关图
自己去对照法则看图说话吧。这个还是很简单,也是很基本的“技能”!
后话1:实际上自相关图(PAC)和偏自相关图(PAC)也可以初步判明一个序列是不是平稳。这一点,我们往往可以用来查看回归残差序列。或者换句话说,如果残差没有明显的特定模式,那么就说回归模型很理想喽!!
后话2:当然,以上通过图形方法来识别还是很为难人的(只是个经验法则而已),其实也可以用更复杂和更高深的定量方法来识别究竟适合做哪一类平稳模型——AR(p)模型,或者MA(q)模型,或者ARMA(p,q)模型,或者ARIMA(p,d,q)模型……。我还是不说了吧,感兴趣的请自行脑补!!
3. 能读懂ARMA(p, q)模型的回归分析报告!!!
例如,能根据回归分析报告,正确写出样本回归函数形式。
下面也给出R软件的回归分析结果:
Series: fultonfish$lprice
ARIMA(2,0,2) with non-zero mean
Coefficients:
ar1 ar2 ma1 ma2 mean
1.47 -0.60 -0.57 -0.074 -0.191
s.e. 0.19 0.14 0.22 0.166 0.063
sigma^2 estimated as 0.0627: log likelihood=-1.7
AIC=15 AICc=16 BIC=32
Training set error measures:
ME RMSE MAE MPE MAPE MASE ACF1
Training set 0.0026 0.24 0.2 Inf Inf 0.95 -0.011ar? ma? mean? 分别是对应什么?请自行复习!
第四部分:联立方程模型
这部分内容请自己看上课ppt和讲义。
考察重点主要是:
联立方程转换成约简形式
联立方程的识别规则(重点还是阶条件识别法则)
两阶段最小二乘法(2SLS)估计联立方程
联立方程回归结果的经济学解释
后话1: 大家还是需要利用经济学知识,多关注回归结果的经济学解释。例如,弹性的概念(又提到它了!);利用供给方程结果和需求方程结果,在给定条件下,计算市场均衡价格和均衡数量!!——经济学的烂账还是要补回来的,欠的账迟早要还啊!
后话2:识别的秩条件还是有点复杂和啰嗦,大家知道它跟阶条件的关系就行!